當應用會需要大量調閱歷史資料來進行統計、計算或呈現的需求時(如:帳務查詢、營銷代理分潤機制等),每次掃描資料庫後計算出結果的方法,效率極差,這導致了使用者必須等待許久時間,才能得到查詢結果。
帳務系統服務時常會提供終端使用者大量的查詢機制,縱使再小的資訊也會提供 API 或 UI 介面供使用者查詢,然而即使資訊量不多,查詢的複雜度卻沒有想像中這麼簡單,時常必須跨多張資料表(Table)才能完成。為了滿足終端使用者千奇百怪的需要,甚至多數時候僅僅只是簡單的聚合工作,沒有複雜的關聯條件。但即使如此,每次使用者呼叫 API 進行資料調閱時,仍會因許多跨表、跨資料庫關聯查詢導致對資料庫產生許多壓力,進而得到一個差勁的系統效能表現。
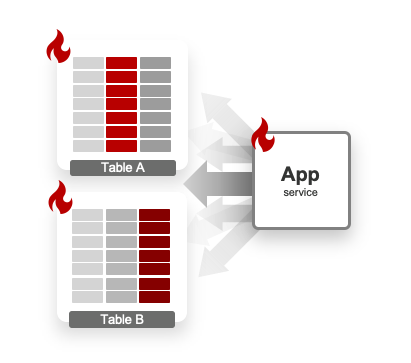
大量併發關聯查詢,會造成效能嚴重衝擊
總歸來說,資料結構依照原始設計,正規化處理後被儲存在各自的資料表之中,只有當應用需要當下,才去從不同的儲存區中把資料拿出來合併,帶來的效能衝擊不言而喻,大致有下列幾點問題:
利用 GRAVITY 的聚合機制,可以讓資料即時被關聯和聚合並落地到一個指定的實體資料表中,然後應用程式可以快速查詢該資料表,而無需做任何關聯式查詢的工作。由於 GRAVITY 只在原始表單資料變更時接收一次事件資料,因而對資料庫系統沒有任何壓力,若是將聚合後的資料寫入到另一個資料庫之中,更是可以實現「讀寫分離」的架構,在微服務架構(MSA, Microservice Architecture)中此種實現更被稱為「命令與查詢權責分離(CQRS, Command and Query Responsibility Segregation)」。
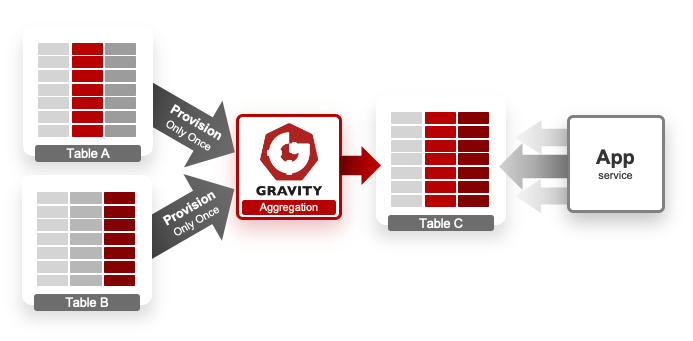
事先預載聚合資料,能減少大量併發查詢所造成的壓力,並保有擴展性
而在面對一些比較複雜的帳務邏輯計算(如:代理分層計算、帳務歸戶等)時,可以在資料落地前自行再開發一層商業邏輯,利用即時資料將結果算好,以便未來查詢使用。
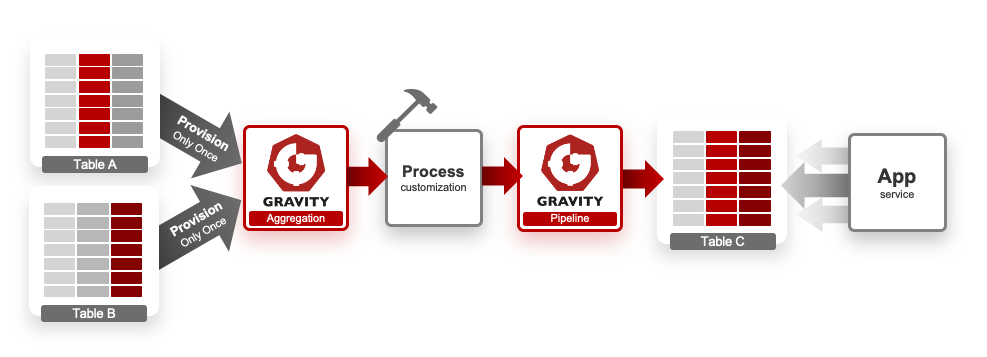
於落地前客製化自己的資料計算處理邏輯
GRAVITY 資料節點都會記錄最後的資料樣態,如果要變更計算規則,只需要把下游資料清除,並從原始資料重新計算一次即可。整條資料鏈路會自然更新下游每一個節點,得到最終的結果。